Plongez dans la construction d'un dashboard Grafana complet. Chaque panneau, chaque requete, chaque astuce expliquee en detail.
L'indicateur roi du suivi de performance industrielle. Voyons comment le construire et l'afficher efficacement dans Grafana.
Le Taux de Rendement Synthetique est l'indicateur de reference en industrie pour mesurer la performance globale d'un equipement. Il combine trois facteurs multiplicatifs :
Temps de production reel divise par le temps d'ouverture. Impacte par les pannes, les changements de serie, les reglages.
Ratio entre la cadence reelle et la cadence theorique. Impacte par les micro-arrets, les ralentissements, les sous-vitesses.
Nombre de pieces conformes divise par le nombre total produit. Impacte par les rebuts, les retouches, les pertes au demarrage.
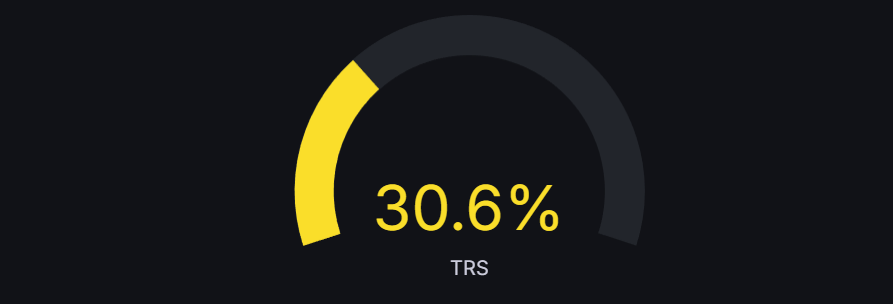
TRS = Disponibilite x Performance x Qualite // Exemple avec notre machine MACHINE_01 : // Disponibilite = 60% (beaucoup de pannes) // Performance = 70% (cadence reduite) // Qualite = 73% (rebuts CPT) // TRS = 0.60 x 0.70 x 0.73 = 30.6% // Objectifs industriels standards : // > 85% = World Class (excellence) // 60-85% = Acceptable // < 60% = Insuffisant, actions requises // Notre machine a 30.6% -> actions urgentes necessaires
La jauge donne une lecture instantanee du TRS. A 30.6%, on voit immediatement que la machine est loin de son potentiel optimal. La couleur jaune indique un niveau d'alerte modere.
Pourquoi une Gauge ? Dans un contexte industriel, les operateurs doivent voir d'un seul coup d'oeil si la machine tourne bien. La jauge semi-circulaire imite un cadran physique : le cerveau humain l'interprete instantanement, contrairement a un chiffre brut ou une courbe. Les seuils de couleurs (rouge/jaune/bleu) renforcent ce message visuel.
Les threshold markers (la bande exterieure rouge/jaune/bleu) permettent de voir ou se situe la valeur par rapport aux zones de performance. Ici, la zone rouge (0-30%) est presque atteinte, ce qui est un signal d'alarme.
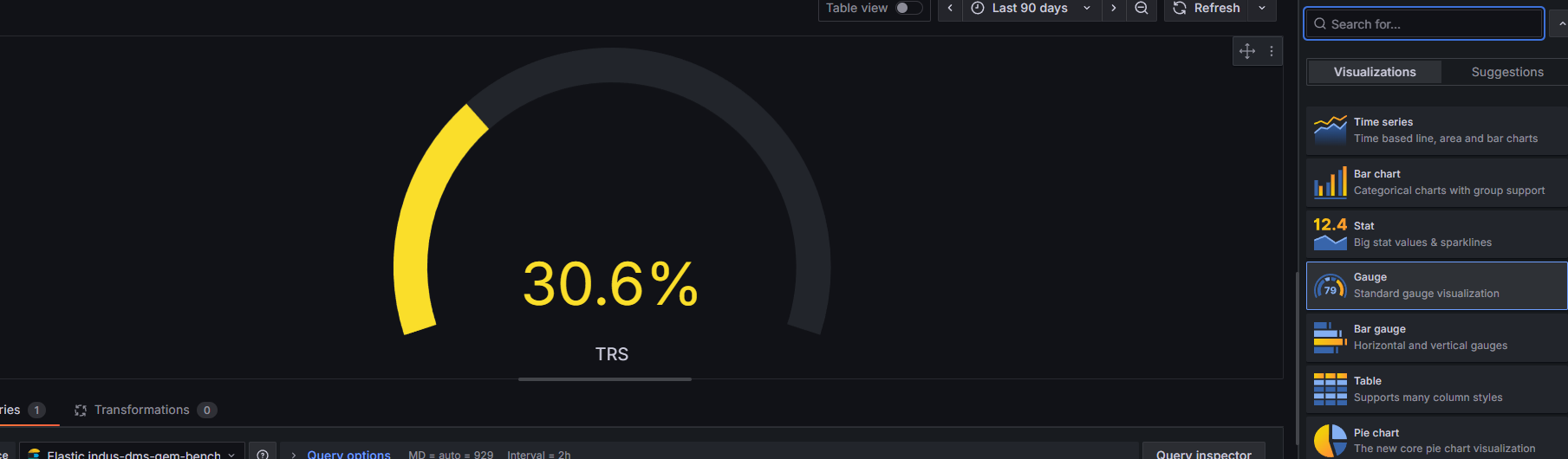
Dans le panneau de visualisation a droite, cliquez sur le selecteur et choisissez "Gauge". Grafana affiche automatiquement une jauge semi-circulaire avec la valeur au centre. L'orientation "Auto" fonctionne bien pour un panneau unique.
La source de donnees est Elastic indus-dms-gem-bench. On utilise le mode Raw Data (et non Metrics) car on veut la valeur brute stockee dans Elasticsearch, pas une agregation. Le Size: 500 recupere les 500 derniers documents correspondants.
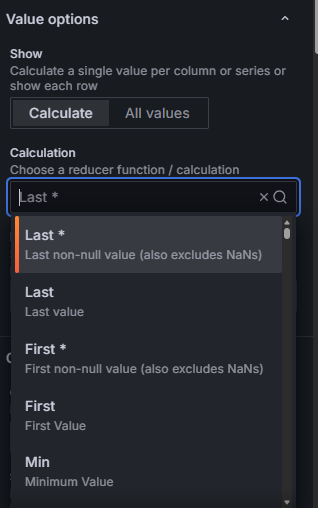
Dans Value options > Calculation, selectionnez "Last *". La difference avec "Last" simple : "Last *" ignore les valeurs null et prend la derniere valeur reelle. C'est essentiel quand les donnees ont des trous (machine eteinte, perte de connexion).
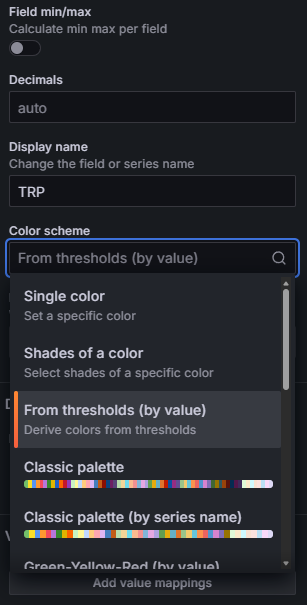
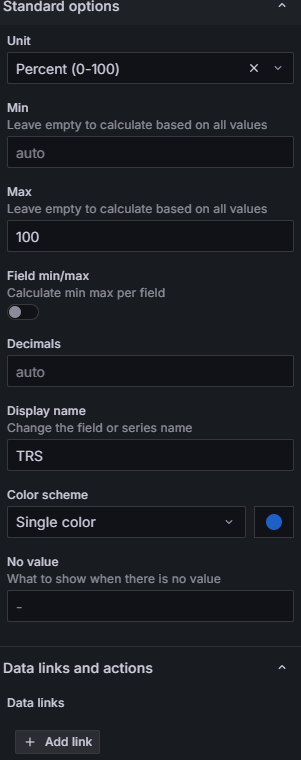
Dans Standard options > Color scheme, choisissez "From thresholds (by value)". Ensuite definissez vos seuils : base verte, 0% orange/jaune, un seuil a 60% bleu. La couleur du chiffre ET de la jauge changent automatiquement selon la valeur.
Dans les options Gauge, activez "Show threshold markers". Cela ajoute la bande coloree exterieure (rouge/jaune/bleu) autour de la jauge qui sert de reference visuelle permanente.
// Requete Elasticsearch pour recuperer le TRS MACHINE_01 AND metrics.custom.name:"TRS" // Type: Raw Data | Size: 500 // Calcul: Last * (derniere valeur non-null)
Le mode Raw Data est ideal quand vous voulez la valeur exacte sans agregation. Combinez-le avec "Last *" pour toujours afficher la donnee la plus recente, meme si des valeurs null existent.
Elasticsearch dans Grafana propose 4 modes de requete. Chacun a un usage different :
metrics.custom.numeric_value, pas une agregation.Regle generale : Utilisez Metrics quand vous avez besoin d'agreger (sommes, moyennes, comptages par periode). Utilisez Raw Data quand vous voulez une valeur ponctuelle (la derniere mesure, un total stocke).
Le graphique Time Series montre l'evolution du TRS sur les 90 derniers jours. On observe un pic autour du 12 decembre (~25%) puis un retour a 0%, indiquant des periodes d'arret de la machine.
Pourquoi un Time Series ici ? Contrairement a la Gauge qui donne une photo instantanee, le Time Series revele les tendances et les patterns. On peut voir quand la machine a ete productive, identifier les periodes de maintenance, et correler avec les pannes. L'intervalle de 1h (Interval = 1h) offre une granularite suffisante sans surcharger le graphique.
avg() of TRS is below 50 sur les 6 dernieres heures.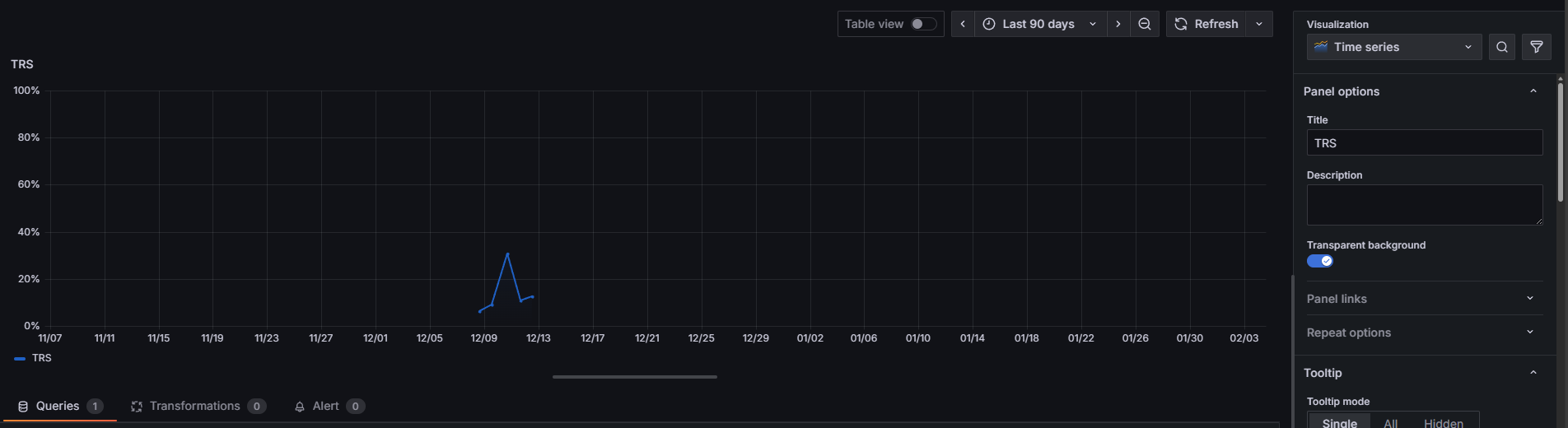

Inclut toutes les pertes : arrets planifies, pannes, sous-performance, defauts qualite. C'est la vision la plus complete de la performance machine.
Quand l'utiliser : Pour les revues de performance globale, les rapports de direction, la comparaison entre machines ou entre usines.
Ici on voit le TRS monter a ~25% autour du 12 decembre puis retomber a 0% quand la machine est arretee.
Mesure uniquement la performance pendant les periodes de production effective. Exclut les arrets planifies (pauses, maintenance programmee).
Quand l'utiliser : Pour evaluer la performance reelle de la machine quand elle tourne. Un TRP eleve mais un TRS bas signifie que le probleme est la disponibilite, pas la machine elle-meme.
Le TRP monte plus haut (~45%) car il ne compte pas les periodes d'inactivite.
Analyse croisee TRS/TRP : Si TRP >> TRS, le probleme est la disponibilite (trop d'arrets). Si TRS et TRP sont proches mais bas, le probleme est la performance ou la qualite en production. Avoir les deux cote a cote permet de diagnostiquer rapidement l'origine des pertes.
Ici, le TRP (~45%) est nettement superieur au TRS (~25%) pendant la periode active. Cela confirme que la machine MACHINE_01 souffre principalement de problemes de disponibilite (pannes frequentes) plutot que de sous-performance quand il tourne.
Quel mode de requete est utilise pour la jauge TRS ?
Un bar chart essentiel pour suivre la frequence des pannes et identifier les tendances. Chaque barre represente le nombre maximum de pannes enregistrees sur une journee.
En maintenance industrielle, le suivi des pannes est fondamental. Il permet de detecter les tendances (les pannes augmentent-elles ?), d'identifier les periodes critiques (y a-t-il des jours plus problematiques ?) et de justifier les investissements en maintenance preventive.
La metrique status-count-Panne est incrementee par le systeme a chaque fois que la machine passe de l'etat "WORKING" a l'etat "Panne". Un compteur eleve sur une journee peut signifier soit beaucoup de petites pannes (micro-arrets), soit des redemarrages frequents apres chaque intervention.
Avec des pics a 17 pannes/jour, la machine MACHINE_01 montre un taux de defaillance preoccupant. La norme industrielle vise generalement moins de 2-3 pannes non planifiees par equipe (8h). 17 pannes sur une journee indique un probleme recurrent qui necessite une analyse des causes racines (methode des 5 pourquoi, diagramme d'Ishikawa).
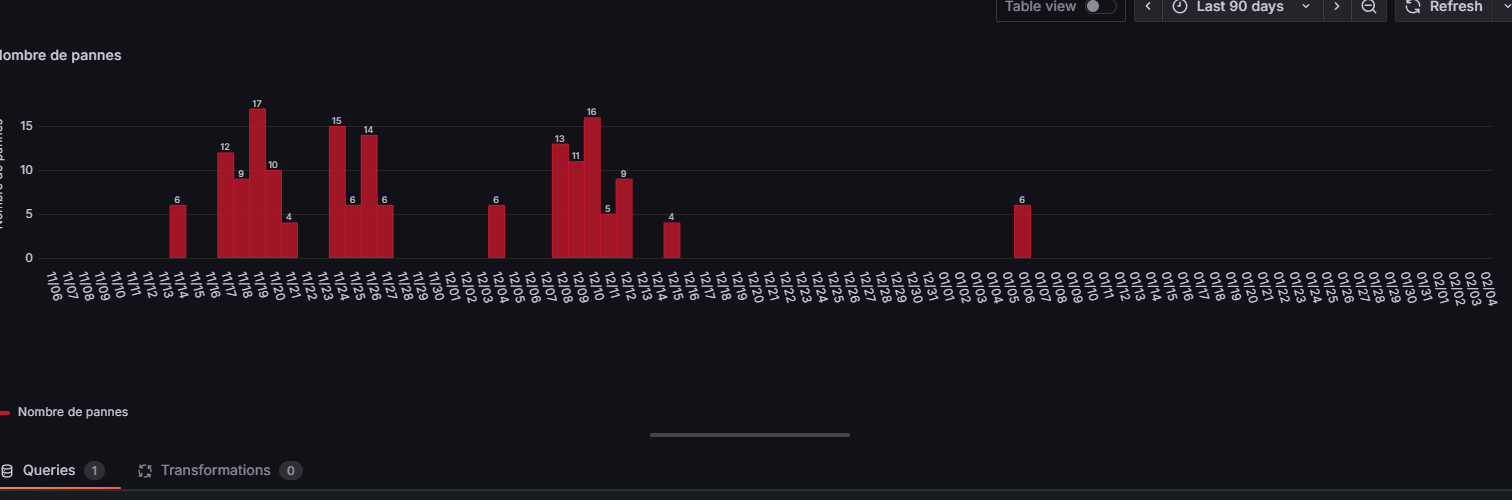
Ce graphique en barres rouges montre le nombre de pannes par jour. On observe des pics a 17 pannes/jour et des periodes plus calmes. L'intervalle est de 1 jour avec un histogramme par date.
Lecture du graphique : Chaque barre rouge represente une journee. La hauteur correspond au nombre maximum de pannes enregistrees ce jour-la. Les periodes sans barre correspondent aux jours ou la machine etait arretee ou sans pannes. On remarque des "clusters" de pannes (groupes de jours consecutifs) ce qui suggere un probleme recurrent plutot que des incidents isoles.
MACHINE_01 AND metrics.custom.name:"status-count-Panne" // Mode: Metrics // Metric: Max on metrics.custom.numeric_value // Group By: Terms on metrics.custom.name.keyword // Then By: Date Histogram (Interval: 1d) // Alias: Nombre de pannes
Connectez-vous au cluster Elastic indus-dms-gem-bench. Ce data source doit etre configure au prealable dans Grafana > Configuration > Data Sources. L'index pattern est indus-dms-gem-bench-metrics qui contient les metriques custom de la machine.
La syntaxe MACHINE_01 AND metrics.custom.name:"status-count-Panne" combine deux filtres : le premier identifie la machine, le second cible specifiquement la metrique de comptage de pannes. L'operateur AND est en majuscule (obligatoire en Lucene). Les guillemets autour de la valeur garantissent une correspondance exacte.
Contrairement au TRS (Raw Data), ici on utilise le mode Metrics car on veut agreger les donnees. L'agregation Max sur metrics.custom.numeric_value recupere la valeur maximale du compteur pour chaque bucket temporel. On utilise Max (et non Count ou Sum) car le compteur est deja incremental dans Elasticsearch - on veut sa valeur max par jour.
Le Group By Terms sur metrics.custom.name.keyword separe les donnees par type de metrique (ici une seule : "status-count-Panne"). Le Then By Date Histogram avec Interval 1d decoupe le temps en buckets d'une journee. C'est cette combinaison qui donne une barre par jour.
Le champ Alias renomme la serie dans la legende. Sans cela, Grafana afficherait le nom technique de la metrique. Un alias clair est important pour les dashboards partages avec des non-techniciens (responsables de production, direction).
La visualisation Time Series est utilisee (pas Bar Chart natif) car elle gere nativement l'axe temporel. La plage "Last 90 days" est choisie pour voir les tendances sur un trimestre. Le MD = auto = 1865 indique que Grafana a automatiquement calcule le nombre max de data points.
Configurez une alerte Grafana (onglet Alert du panneau) : condition WHEN max() OF Nombre de pannes IS ABOVE 10. Envoyez vers Slack, email ou PagerDuty. Definissez un "For" de 0s pour alerter immediatement ou 1h pour filtrer les faux positifs.
Ajoutez une seconde requete ou utilisez Transformations > "Add field from calculation" pour afficher une courbe de tendance lissee. Ca permet de voir si la situation s'ameliore ou se degrade au-dela du bruit quotidien.
Creez une source d'annotations dans les Dashboard Settings qui requete les evenements de maintenance. Chaque intervention apparaitra comme une ligne verticale sur le graphique, permettant de correler "maintenance effectuee = moins de pannes apres".
Ajoutez un panneau Stat a cote qui affiche le total cumule des pannes sur la periode, la moyenne par jour, et le jour avec le plus de pannes. Utilisez les transformations "Reduce" pour calculer ces valeurs.
Completez avec des indicateurs MTBF (Mean Time Between Failures) et MTTR (Mean Time To Repair). Ce sont les KPIs de maintenance les plus importants. Creez des requetes qui calculent le temps moyen entre deux pannes et le temps moyen de reparation.
Si les causes de pannes sont documentees, creez un diagramme de Pareto (bar chart horizontal trie par frequence) pour identifier les 20% de causes qui generent 80% des pannes. Utilisez un Bar Chart natif avec Group By sur le type de cause.
Un Fill opacity de 80 donne des barres bien opaques sans etre completement solides, ce qui les rend plus esthetiques.
Quelle agregation est utilisee pour compter les pannes ?
Un stacked bar chart pour visualiser la repartition du temps entre les differents etats de la machine. Essentiel pour comprendre comment le temps de production est consomme.
En industrie, chaque minute de production compte. Le graphique "Etat de la machine" decompose chaque journee en blocs de temps : combien d'heures la machine a travaille, combien d'heures elle etait en panne, inactif, en erreur, etc. C'est le pilier du calcul de disponibilite (le D du TRS).
L'axe Y est en heures (0-10h), ce qui correspond a une journee de travail typique. Si la barre verte (WORKING) ne remplit pas les 8-10h, c'est que du temps est perdu. Les barres empilees (stacked) montrent exactement ou va le temps perdu.
Comment lire ce graphique : Pour chaque jour, la hauteur totale de la barre empilee devrait atteindre ~8-10h (temps d'ouverture). La proportion de vert (WORKING) par rapport au total donne directement le taux de disponibilite de la machine ce jour-la.
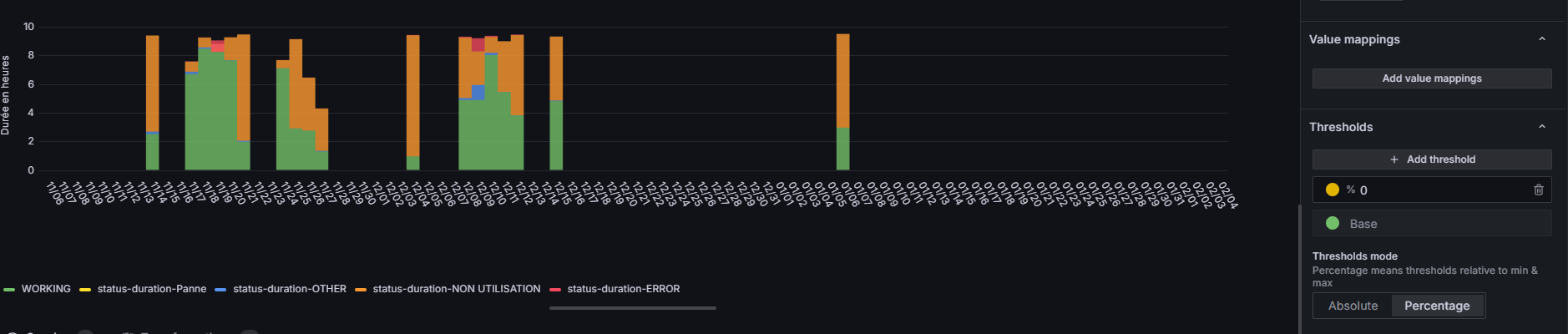
Machine en production active. C'est l'etat souhaite : la machine execute son programme de production. Plus cette duree est longue par rapport au temps d'ouverture, meilleure est la disponibilite. Objectif : >85% du temps d'ouverture.
Arret non planifie de la machine. Chaque minute de panne est une perte directe de production. Les causes typiques : defaut capteur, bourrage, casse d'outil, defaut electrique. A minimiser en priorite.
Activites hors production : changement de serie, reglages, essais, nettoyage. Ce temps est partiellement reducible par du SMED (Single Minute Exchange of Die) et de l'optimisation des procedures.
La machine est disponible mais non utilisee : pauses, manque de pieces en amont, attente d'un operateur, fin de commande. Indique des problemes d'organisation ou de flux logistique.
Erreur systeme de la machine : bug logiciel, defaut de communication, alarme securite. Souvent plus grave qu'une panne classique car peut necessiter un reboot complet ou une intervention constructeur.
MACHINE_01 AND metrics.custom.name:"status-duration-*" // Le wildcard * capture tous les etats : // status-duration-Panne // status-duration-OTHER // status-duration-NON UTILISATION // status-duration-ERROR // (+ WORKING via override) // Metric: Max on metrics.custom.numeric_value // Group By: Terms (metrics.custom.name.keyword) // Then By: Date Histogram (Interval: 1d)
Le wildcard status-duration-* capture toutes les metriques de duree. L'override renomme status-duration-WORKING en simplement WORKING pour la lisibilite.

Les overrides permettent de modifier les proprietes d'une serie specifique sans affecter les autres. C'est un outil puissant de Grafana.
status-duration-WORKING est renomme en "WORKING" via Display name. Sans cela, la legende afficherait le nom technique complet, peu lisible.status-duration-* retourne toutes les series correspondantes. Leurs noms techniques sont longs. Les overrides permettent de les humaniser un par un.Pour ajouter un override : panneau droit > Overrides > "Add field override" > "Fields with name" > selectionnez le champ > ajoutez les proprietes (Display name, Color, etc.)
WORKING / (WORKING + Panne + OTHER + ...). Cela donne directement le taux de disponibilite par jour.Des jauges et statistiques pour chaque type de composant : Simple, Double, Milieu - Gauche et Droite.
CPT (Composant Par Type) correspond aux differents composants utilises par la machine de production. La machine MACHINE_01 utilise 6 types de composants, organises par position (Gauche/Droite) et par geometrie (Simple, Double, Milieu).
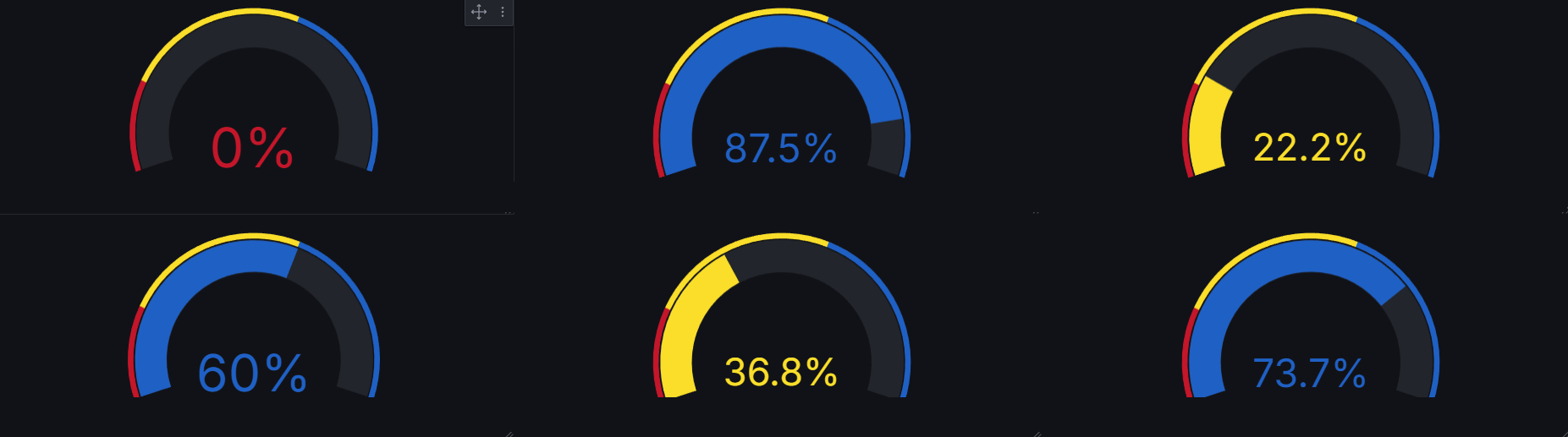
Chaque composant a un taux de reussite (le pourcentage affiches dans les jauges) qui indique la proportion d'operations conformes realisees avec ce type. Un taux faible signifie que le composant est use, mal aligne, ou incompatible avec le type de piece.
Analyse : Le desequilibre entre Gauche et Droite (87.5% vs 36.8% pour le type Double) suggere un probleme mecanique d'alignement ou d'usure asymetrique. Les composants "Simple" sont les plus variables (0% a 60%), ce qui indique un besoin de standardisation des parametres de production.
Chaque jauge represente le taux de reussite d'un type de composant. Les couleurs changent automatiquement selon les seuils configures : rouge < 30%, jaune 30-60%, bleu > 60%.
Chaque jauge est un panneau Grafana independant avec sa propre requete. Les threshold markers (barre exterieure coloree) et le schema de couleur "From thresholds (by value)" font que la couleur du chiffre et de la jauge changent automatiquement.
MACHINE_01 AND metrics.custom.name:"CPT1_G-total" // Mode: Raw Data | Size: 500 // Value options > Calculation: Last * // Standard options > Unit: Percent (0-100) // Standard options > Min: 0 / Max: 100 // Pour chaque jauge, changez le nom de metrique : // CPT1_G-total (Simple Gauche) // CPT2_G-total (Double Gauche) // CPT3_G-total (Milieu Gauche) // CPT1_D-total (Simple Droite) // CPT2_D-total (Double Droite) // CPT3_D-total (Milieu Droite)
$epf_type avec les 6 valeurs et un seul panneau qui utilise la variable dans la requete. Le repeat feature de Grafana generera automatiquement les 6 jauges./d/epf-detail?var-type=CPT1_G.Les seuils utilisent le code couleur industriel : rouge < 30%, jaune 30-60%, bleu > 60%. Les markers exterieurs rendent la lecture tres intuitive meme a distance sur un ecran d'atelier.
Le panneau Stat affiche le nombre total brut : 103 pour CPT1_G-total. Le fond vert avec le grand chiffre rend l'information immediatement lisible, meme sur un ecran d'atelier a 5 metres.
Pourquoi le panneau Stat ? Quand l'information se resume a un seul chiffre important, le Stat est le meilleur choix. Le nombre 103 represente le total cumule d'operations realisees avec le composant CPT1_G. Ce n'est pas un pourcentage mais un compteur absolu. Le fond colore (vert) est genere automatiquement par les thresholds, indiquant que cette valeur est dans la zone "normale".
Dans le selecteur de visualisation, choisissez "Stat". Il affiche un grand chiffre avec optionnellement un sparkline (mini graphique) en arriere-plan.
Requete : MACHINE_01 AND metrics.custom.name:"CPT1_G-total" en mode Raw Data, Size: 500. Le mode Raw Data recupere les documents bruts pour obtenir la valeur exacte du compteur.
Le mode "Calculate" applique une fonction de reduction aux donnees. "Last *" prend la derniere valeur non-null. L'alternative "All values" afficherait chaque valeur individuellement (utile avec un repeat panel).
Le fond vert est genere par le Color scheme "From thresholds (by value)". Grafana colore le fond du panneau entier selon les seuils definis. Sans seuils, le fond serait gris neutre.
L'intervalle est de 6h car Grafana calcule automatiquement le "max data points" (304) en fonction de la largeur du panneau et de la plage temporelle (90 jours). Pour un Stat, l'intervalle importe peu car seule la derniere valeur est utilisee.

Quel type CPT a le meilleur taux de reussite ?
Les types de visualisation, les options de style, et les bonnes pratiques pour un dashboard efficace.
Evolution du TRS et TRP dans le temps. Ideal pour les tendances.
Nombre de pannes et etat de la machine. Parfait pour les comparaisons.
TRS et CPT en pourcentage. Lecture instantanee avec seuils visuels.
Totaux CPT. Un grand chiffre lisible de loin sur ecran industriel.
Tout le dashboard repose sur le data source Elastic indus-dms-gem-bench. C'est un cluster Elasticsearch qui stocke les metriques de la machine dans un index indus-dms-gem-bench-metrics.
Allez dans les parametres Grafana, section Data Sources, et cliquez "Add data source". Cherchez "Elasticsearch".
Renseignez l'URL de votre cluster Elasticsearch (ex: http://elasticsearch:9200). Si vous utilisez une authentification, configurez les credentials dans la section Auth.
Entrez le pattern d'index : indus-dms-gem-bench-metrics. Si vos index sont journaliers (ex: indus-dms-gem-bench-metrics-2024.12.01), utilisez le pattern avec wildcard.
Selectionnez le champ de timestamp : generalement @timestamp ou metrics.date. C'est ce champ que Grafana utilise pour l'axe temporel.
Cliquez "Save & Test" pour verifier la connexion. Un message vert confirme que Grafana arrive a se connecter et a trouver l'index.
Chaque document dans l'index contient les metriques custom de la machine. Voici la structure utilisee :
{
"@timestamp": "2024-12-10T08:30:00Z",
"machine": "MACHINE_01",
"metrics": {
"date": "2024-12-10",
"custom": {
"name": "TRS", // Nom de la metrique
"numeric_value": 30.6 // Valeur numerique
}
}
}
Les metriques disponibles dans metrics.custom.name : TRS, TRP, status-count-Panne, status-duration-*, CPT*_G-total, CPT*_D-total.
Toutes les requetes de ce dashboard utilisent la syntaxe Lucene. Voici les elements essentiels utilises :
// === OPERATEURS DE BASE === MACHINE_01 // Recherche du terme dans tous les champs metrics.custom.name:"TRS" // Recherche exacte dans un champ specifique MACHINE_01 AND metrics.custom.name:"TRS" // Combinaison (AND en majuscule !) // === WILDCARDS === metrics.custom.name:"status-duration-*" // * = n'importe quelle suite de caracteres metrics.custom.name:"CPT?_G*" // ? = un seul caractere // === CHAMPS .keyword === metrics.custom.name:"TRS" // Champ text (analyse, tokenise) metrics.custom.name.keyword:"TRS" // Champ keyword (exact, pour Group By) // === BONNES PRATIQUES === // Toujours utiliser .keyword pour les Group By Terms // Toujours mettre les valeurs entre guillemets si elles contiennent des espaces // AND/OR/NOT doivent etre en MAJUSCULES
Utilisez des Display names clairs (TRS, TRP, WORKING) et des alias dans les requetes. Les non-techniciens doivent comprendre chaque panneau sans explication. Evitez les noms de champs bruts dans les legendes.
Definissez des seuils qui correspondent aux standards industriels : TRS > 85% = World Class, > 60% = acceptable, < 60% = critique. Chaque seuil doit declencher une action concrete.
Activez "Transparent background" sur chaque panel pour une integration visuelle propre. Les panneaux se fondent dans le fond sombre et l'ensemble parait plus professionnel.
1h pour les time series (detail), 1d pour les bar charts (vue jour), auto pour les stats. Le parametre MD (Max Data Points) controle la granularite. Trop de points = lenteur, pas assez = perte d'info.
Le wildcard status-duration-* capture 5 metriques en une requete. C'est plus efficace que 5 requetes separees et assure que les nouvelles metriques sont automatiquement incluses.
Les field overrides permettent de personnaliser chaque serie : renommer status-duration-WORKING en "WORKING", fixer des couleurs par etat, masquer des champs inutiles.
Creez des variables pour le nom de la machine ($machine) et la periode. Un seul dashboard sert alors pour toutes les machines de l'usine. Les utilisateurs selectionnent via un menu deroulant.
Configurez les permissions du dashboard : lecture seule pour les operateurs (pas de modification accidentelle), edition pour les superviseurs. Utilisez les Teams Grafana pour gerer les acces.
Le flux de donnees de la machine jusqu'au dashboard Grafana :
Uploadez un screenshot de votre dashboard Grafana et laissez l'IA analyser automatiquement votre dashboard pour vous donner un score et des recommandations personnalisees.
ou cliquez pour selectionner une image (PNG, JPG)
Selectionnez tous les types presents sur votre dashboard.
Les thresholds changent la couleur des panneaux selon la valeur (vert/orange/rouge).
Les titres et series utilisent-ils des noms metier plutot que des noms techniques bruts ?
Les axes et valeurs affichent-ils des unites (%, secondes, octets...) ?
Les graphiques multi-series affichent-ils une legende pour identifier chaque courbe ?
Recevez-vous des notifications quand une valeur depasse un seuil critique ?
Des menus deroulants en haut du dashboard permettent-ils de filtrer (machine, periode, etc.) ?
Les panneaux sont-ils regroupes par theme avec des lignes (Rows) et une hierarchie claire ?
Les panneaux ont-ils un fond gris individuel, ou un rendu unifie avec fond transparent ?
Des marqueurs sur les graphiques indiquent-ils des evenements (deployements, incidents, maintenance) ?